如果不记笔记就等于没学,一定程度上我体会到这点了。现在记录下40页PPT记录2025年年中AI行业共识【视频播客】_哔哩哔哩_bilibili的观后感。
1.缺少评价AI大模型能力的数据集
根据他给出来的OPEN AI的研究显示现在的AI大模型数据集都做到很顶峰的级别,导致你没有办法判断AI模型的能力;其实这一点也有一些论文讨论过,就认为现在的大模型训练效果好有可能是没有做足够的数据去重,这些训练集上的好表现有可能是过拟合的结果。
而根据自己的认识,这些模型基线的评测也有局限,做选择题,做多选题的多,评价答案的少。而评价答案生成能力,往往是直接拿另外一个大模型来打分。毕竟数据量那么大,不可能人工评估。我想这大概就是我们需要微调,让他更适合业务场景的原因之一——表现好的大模型有可能是过拟合的,表现好的大模型也不一定适配你的业务场景。当然,更多的我想还是私有知识库的问题。
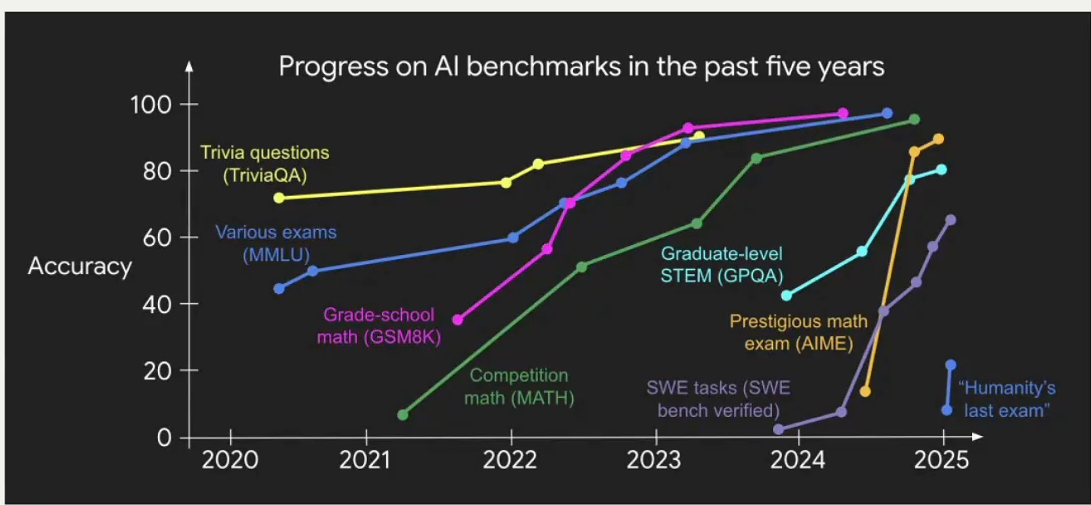
2.模型的能力提升
这个倒是常见了,就是模型的一个进化过程,从预训练堆积数据集,到GPT3.5注重模型的后训练,最后到RL强化学习阶段,让大模型自己更新自己的能力。从open ai 的RLHF,Anthorpic的RLAIF,斯坦福大学的DPO,DS的GRPO都是在搞这些。有意思的是,这些算法都是在RLHF的不同维度上做减法——减少同时训练的模型数量,用AI的数据代替人类的数据,也就是CAI。

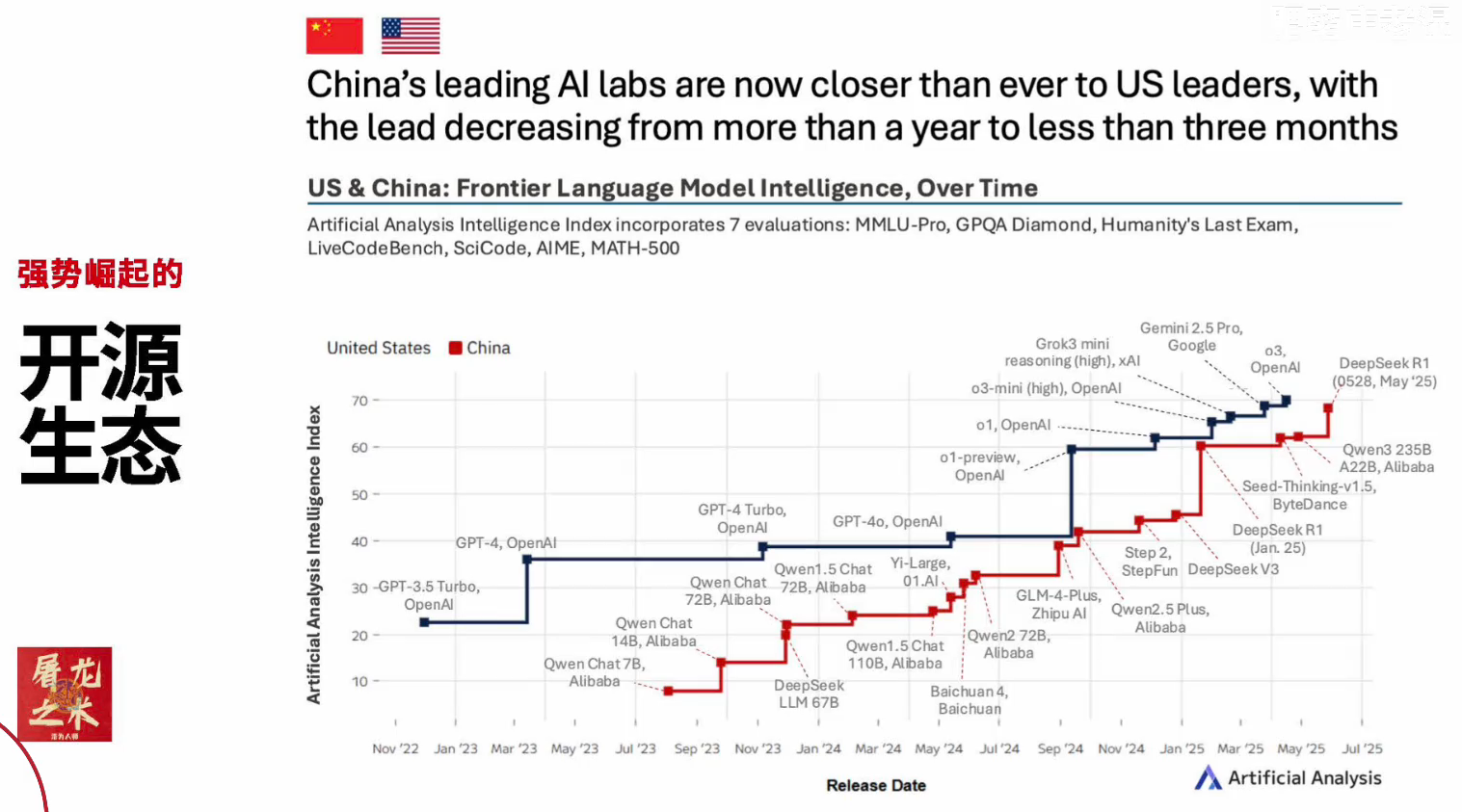
3.开源也是行业趋势
一定程度上我能理解开源可以增加技术迭代的速度,有人帮你踩坑,你肯定自己研发就有更多思路。但另一方面,我实在不太理解开源能带来哪些经济上的收益
【今年最多的开源关注是智能体,然后是coding,最后是inference这样的基础设施】
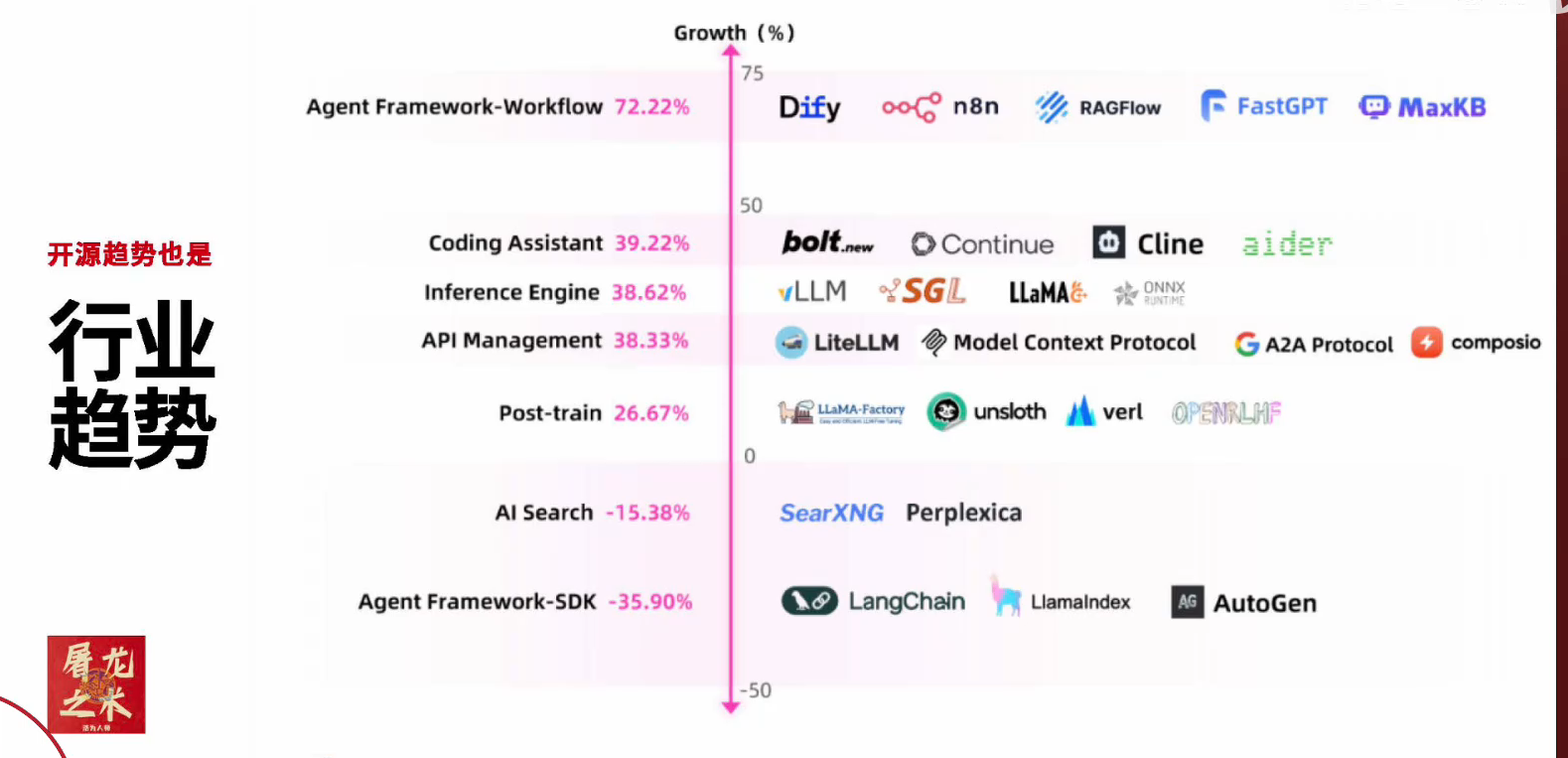
这个报告真是不错,由蚂蚁开源在 2025 年 5 月 27 日第十届技术日发布,源连接:https://antoss-landscape.my.canva.site

4.产品
趋势之一是有大量Agent应用产生,这个很常见。但是浏览器这个我还真是不太清楚。谷歌我记得有一个问题是被政府拆分啥的。夸克的AI高考报名,然后腾讯也在接近。
这个也就是搜广推这三大业务吧,只是换上大模型作为核心。

他提到运营上也很有意思:现在的环境允许发布的产品是内测阶段。就比如cursor,这个东西都一年多了,才推出1.0。不过,现在的用户能接受使用产品,等他的成长,但等成熟的产品出现后,再想做这个东西,一定就会面临没有用户愿意来,导致没有足够数据更新的困境吧
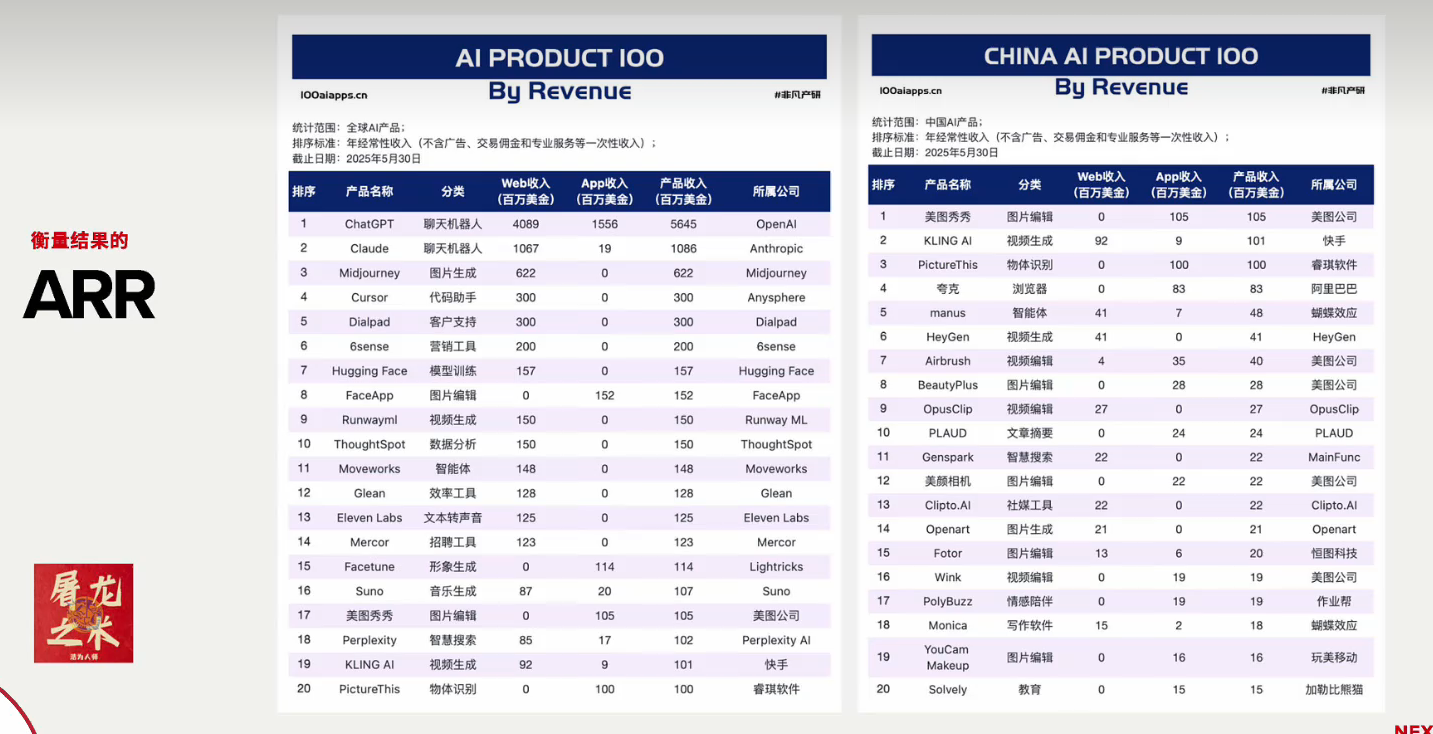
这个榜单值得一看:
今年是并购大年

最后指出这个协议也是一个很好的发展机会,不过这玩意不是大公司真的能玩吗?
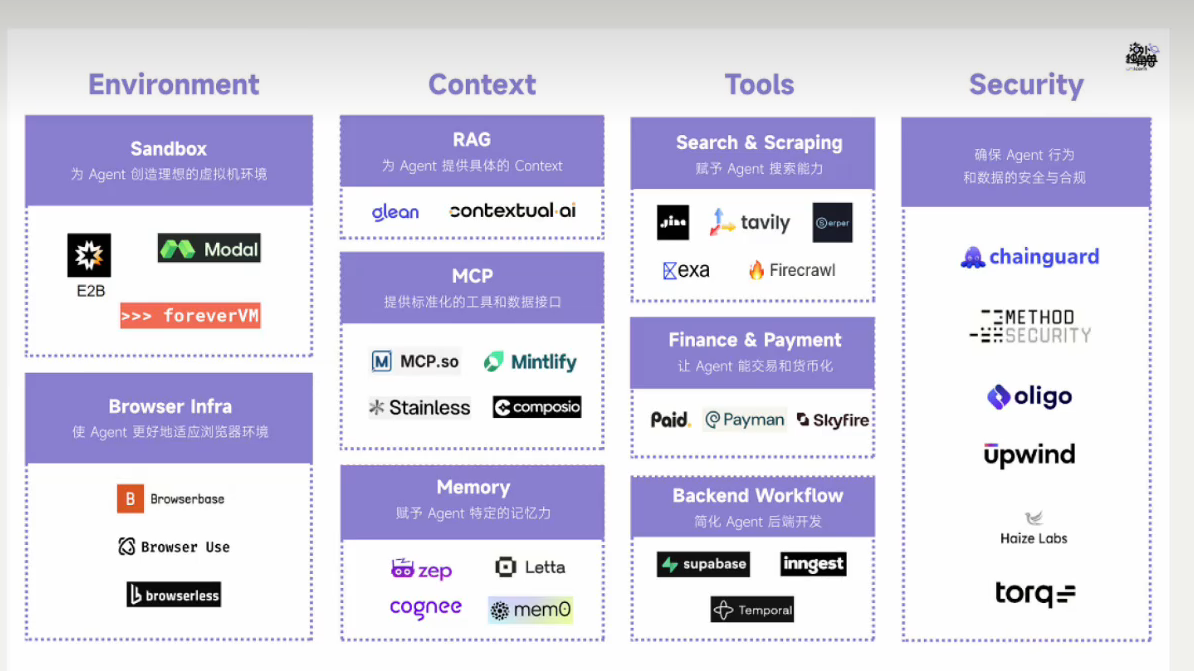
参考资料:
1.40页PPT记录2025年年中AI行业共识【视频播客】_哔哩哔哩_bilibili
2.蚂蚁开源最新报告:Agent 框架热潮褪去,大模型开发已经进入“生死局”_2025 模型开源开发 态全景与趋势-CSDN博客