训练显存消耗(可估算部分)主要包括:模型参数(Model)+ 优化器状态(Optimizer status)+梯度值(Gradient)+激活值(Activation)。根据数值的变化,可将显存消耗分为静态/动态值。训练过程中,模型参数、优化器状态一般不会变化,这两部分归属于静态值;激活值、梯度值会随着计算过程发生变化,将它们归类到动态值。
我们部署大模型的时候一般只会用到模型参数(Model)+ KV缓存(激活值),其中,当我们使用MOE架构的模型时,模型参数往往是整个模型的10%-15%左右。
1.为什么不缓存Q,只需要缓存KV?
对于n个token,我们假设他拥有n*n的qkv矩阵。当我们生成n+1个token时,前n行的结果都是固定的。如图所示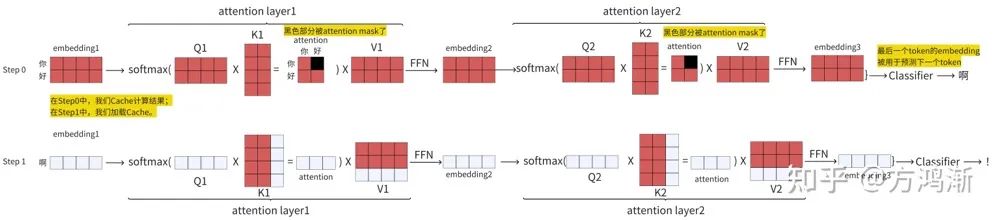
可以看到红色部分的结果都是一致的。只是第N+1个token在计算时需要前面保存的KV矩阵。而Q矩阵则只会使用到N+1个token对应的那个部分。
也是因为这个原因,模型在Step0阶段才需要大量计算QKV,是计算密集型任务。到了Steo1,就只需要访问保存的KV矩阵就可以了。通过KV缓存,模型的消耗从生成NN的多个矩阵变成了1N的矩阵和对之前的N*N矩阵的访问,也就是访问密集型任务。
总结一下:我们只需要 embedding 的最后一行,所以我们也只需要 attention 的最后一行,因此只需要 Q 矩阵的最后一行。缓存的是 K 和 V 矩阵即可。
2.模型的参数如何计算?
关于这个问题,我们首先均考虑Float16量化的情况。在推理的过程中,我们主要的模型指出是KV缓存+模型参数。
模型参数由三部分构成:
1.包括QKV和多头注意力矩阵聚合的矩阵,一共四个,也就是4NN的计算量,N表示维度。
2.然后是Eme’bedding的计算,假设输入的token被分为N个维度,词表大小为V,那就需要VN,输入输出都需要Emebedding,就是2VN.
3.最后是全连接层,扩大四倍,缩小四倍,就是4NN2
对于每一层Trans有12N*N+2VN的消耗,对于flaoat16的情况,就还需要再翻倍
然后是KV缓存,他的计算公式是2Nlength*B.这里面的B表示批量,length表示token长度,同样的,对于Float16我们需要翻倍计算
因此,最终我们算出在FLOAT16的情况下,推理单层TRANS消耗24NN+4VN+4NBlength的参数,也可以简化下来只算自注意力层
3.训练阶段的显存消耗如何计算?
推理部分好像有点写错了,那个是用VN来算显存,这里是在用参数来算,EMMMMM,坏了。算了,反正改了
现在跟着这位大佬的思路走,主要是做个补充说明。一个字节(B)=8个比特(bit),float16,float32值得就是多少个比特位来表示一个参数,因此对于floatX的参数类型,就是X/8个字节的消耗。然后就是1024,这个是1MB=1024KB;1KB=1024B这个逻辑来的,因此简化计算对于X(B),FLOAT32的模型就是32/8 * X(B)=4XGB的显存消耗
这里的Momentum指的是动量,表示之前更新的内容对现在的内容的影响程度,Variance是方差,是用来使得计算波动变小,更稳定用的,一般来说这两个值都是取Float32,也就是4个字节,再加上副本就是(4+4+4)了
梯度就是权重矩阵对每一个隐藏层的偏导,表示的是这次更新的方向。
激活值这个我就不是很看得明白了,当作结论记住吧。
参考文献:
- https://zhuanlan.zhihu.com/p/687226668
- https://ai.stackexchange.com/questions/48185/why-not-cache-the-q-query-matrix?utm_source=chatgpt.com
- https://blog.csdn.net/m0_63171455/article/details/145123745
- https://www.bilibili.com/video/BV1NZ421s75D/?spm_id_from=333.337.search-card.all.click&vd_source=ecbe42ffb25fea0da636165433fb75d6