在这里更新下我对混合专家(mixture-of-experts, MoE)的理解:MOE是一种通过对Transformer的FNN处进行简化的方法。首先将FNN层分成N个专家,每次只激活需要的那个专家模型,这样推理的时候就能减少计算量到原来的1/N。然后通过均衡训练的方法保证训练阶段每个专家模型都能充分训练。
这样做的好处就是能够保障模型的可部署性和输出速度符合我们阅读速度的需求。毕竟你训练的时候不考虑成本,但是你推理的时候,总是要考虑这个问题的。
不过,这只是一个浅显的认识。具体的内容我还得跟着视频学习,更新。
这个图总结得真好啊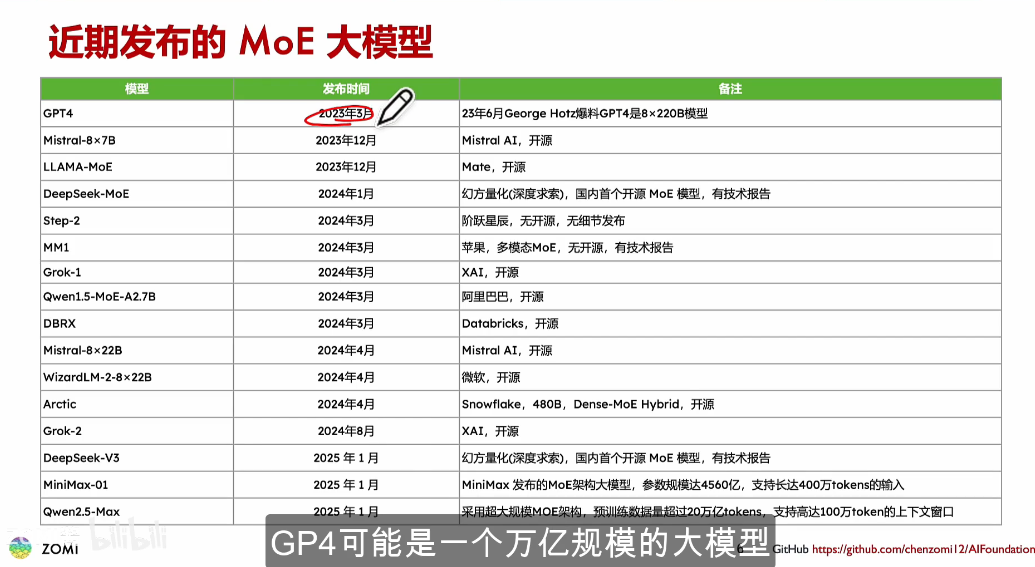
##MOE的结构##
正如之前说过的,Moe会将FNN分为多个Expert专家模型,如何选择合适的专家模型就成为一个问题。在这里我们会采用一个门控机制,通过Softmax这样的算法将对专家模型的选择变成概率值,并根据这个将特征输入到合适的专家模型去。
根据处理机制不同,就会分成三种类型(1)稀疏门控:只激活部分专家(2)稠密门控:激活全部专家(3)软门控(这个没看懂).我想这个还是去看最新大模型有哪些架构就好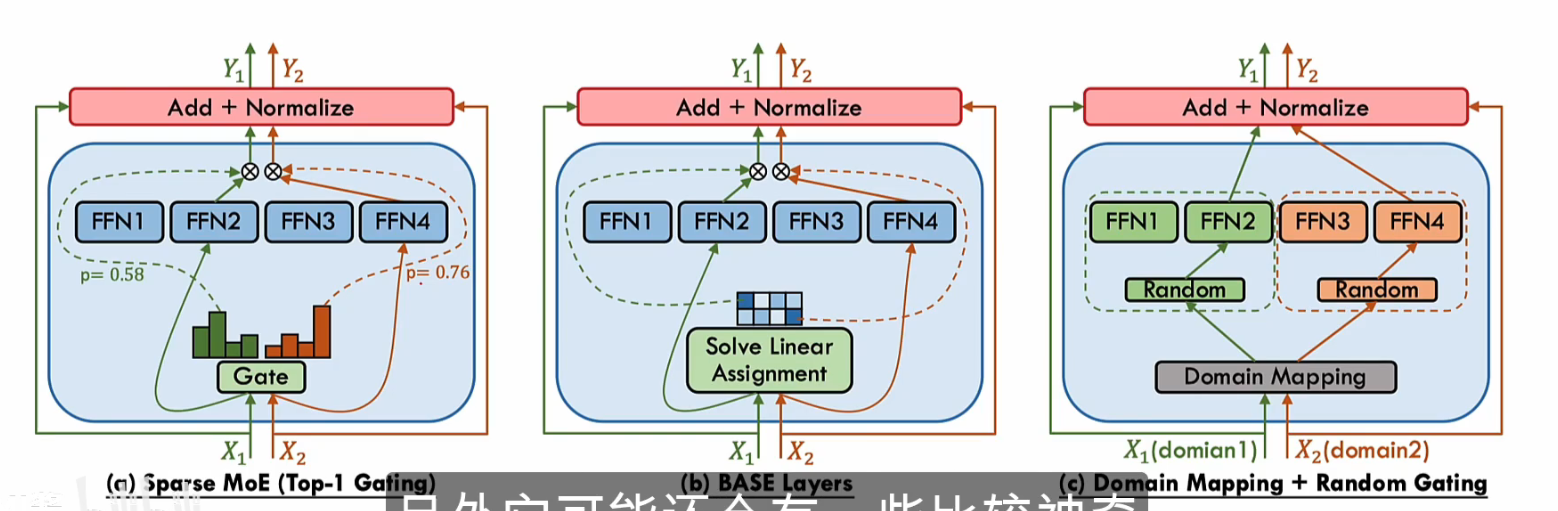
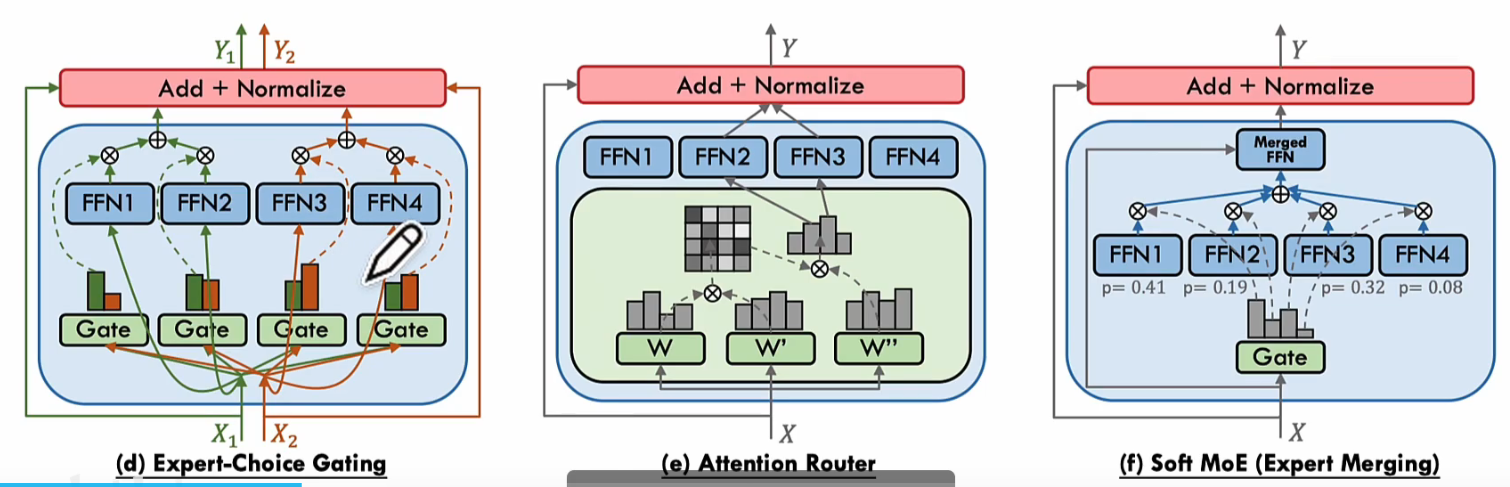
PS:
不得不说,博客一旦停下来就很难继续写,总之先以每两天更新一次为目标。此外,我觉得自己也该赶紧把评论功能加上去。虽然可能没人看就是了。
B站的ZOMI酱大佬和他的项目真是太厉害了。
参考学习文献:
https://www.bilibili.com/video/BV1y7wZeeE96?spm_id_from=333.788.videopod.sections&vd_source=ecbe42ffb25fea0da636165433fb75d6
https://github.com/chenzomi12/AIInfra